はじめに
この記事は、Machine Learning Advent Calendar 2016の11日目の記事です。
機械学習のアルゴリズムに関する記事は検索すればたくさん見つけることができます。
しかし、実際にどのように仕事で導入しどのように運用するのかについての記事は少ないように思います。
私は過去に2つほど機械学習を用いたプロジェクトを企画からリリースまで行いました。
そして、今新たにもう1つ機械学習を用いたプロジェクトを立ち上げようとしています。
過去の2つは既存システムに機械学習アルゴリズムを導入したもの、今進行しているのは機械学習がなければ成り立たないシステムの構築です。
十分な経験を持っているとは言えませんが、それなりにたくさんの学びがあったので、誰かの参考になればと思い共有させていただきます。
ちなみに、個々の手法の詳しい解説は他のサイトに任せて、この記事では本番リリースまでの流れのみを紹介しています。
基本的な流れ
私は以下のような流れで提案から本番導入まで行いました。
- 機械学習を導入することによってKPIが向上する箇所の発見
(場合によっては新規サービス) - KPIの向上見込みの試算
- オフライン評価用のシステム設計・A/Bテスト用の方法およびシステム設計・100%リリース用のシステム設計
- 工数を獲得するための承認
(場合によってはオフライン評価の結果が出てから行う) - オフライン評価用のシステム詳細設計・構築・テスト
(必要であればリリース) - オフライン評価
(必要であればチューニング、テスト環境などを変更して再実施) - A/Bテストを実施するための承認
(ステップ3で実施していない場合は、ここまで自由時間でやってここで工数の承認も得る) - A/Bテスト用のシステム詳細設計・構築・テスト
- A/Bテスト
(必要であればチューニング、テスト環境などを変更して再実施) - 100%リリース承認
- 100%リリース用のシステム詳細設計・構築・テスト
- 100%リリースと最終評価
私は複数のサービスについて、ときには提案から、設計・開発・テスト・保守・運用までやるなんでも屋な感じです。また、ウォーターフォール的なプロセスで進めることが多い職場なので、こういう流れを踏んでいます。
環境によっては特定のステップを飛ばしたりできると思います。例えば、常に何らかのアルゴリズム精度向上などに時間を取れる人の場合は、最初のステップ1,2,4あたりはスキップできると思います。
場合によってはオフライン評価が難しい場合もあります。その場合は、オフライン評価をスキップしていきなりA/Bテストをやることになります。
新規サービスの場合はA/Bテストの部分がβリリースになるかと思います。候補アルゴリズムが複数ある場合は新規サービスであったとしてもA/Bテストを行う場合もあると思います。
A/Bテストではなくバンディットアルゴリズムを使っても大丈夫です。私の場合は、A/Bテスト期間中のロストを減らすよりも、AとBの手法の詳細な分析結果を出す必要があるので、A/Bテストを使っています。
以下で各ステップについて解説します。
機械学習とは関係が無い部分はスキップしていきます。
各ステップの解説
1. 機械学習を導入することによってKPIが向上する箇所の発見
ここは機械学習にかかわらず、通常の提案と同じになります。
現状のサービスで提供出来ていない機能は何か。また、今までに使ってない情報を使ったり、方法を変えることで既存のシステムを改善出来ないかを考えます。
例えば、既存のサービスにおすすめの商品や記事を提示するといったレコメンデーションの機能がなければ、それを検討してみるといいかもしれません。イメージしやすく、かつ実装も簡単で効果が出やすいと思います。

この時に重要なのは仮説を立てることだと思います。仮説を立ててみて、それを立証するためのデータを分析して探す。そして、仮説が正しくなければ新たに仮説を立てる、というのを繰り返すと進めやすいです。
2. KPIの向上見込みの試算
ここも機械学習にかかわらず、通常の提案と同じになります。
どの程度向上するかの試算は難しいところで、実際にはやってみないと分かりません。
とはいえ、私のような何でも屋が機械学習のプロジェクトを実施する際には、上司や事業部を納得させるために必要になります。
私が取っていた基本的な戦略は、他部署・他社あるいは論文から、似たような状況でどのアルゴリズムを導入してどの程度(何%)KPI(Key Performance Indicator)が改善されたかが分かる事例を見つけます。
そして、それを自部署のシステムに適用して見込みを試算します。その際、経験的に何らかの係数を乗じるた方が良いと分かっていたら、その係数を加えます。
今までの経験上、報告されているほどの効果は出ないです。
また、他の事例とほぼ同じ状況なのにユーザー層や扱っているものの違いで全く効果がなかったりします。
当たり前ですが、オフラインの評価をやってから工数の承認を取れる状況の人は、オフラインの評価を元に上司・事業部に提案した方がより正確な試算が出来るので承認が得やすいです。
また、A/Bテストの結果もある程度予想できるので、安心感があります。
3. オフライン評価用のシステム設計・A/Bテストの方法およびシステム設計・100%リリース用のシステム設計
ステップ4で上司や事業部に提案する際の工数を出すためと、システム・運用・テスト方法などが現実的かどうかを確認するために、この段階である程度設計をします。
オフライン評価、A/Bテストの段階でKPIが改善される見込みがなければ100%リリースは不可能なので、それぞれ最短の仕組みで検討すべきです(もちろん、100%リリースするときに作り直しが必要になるようではダメですが)。
オフライン評価は基本的にはバッチを開発のみでの実施を検討、A/Bテストは本番の100%の負荷に耐えれる想定で開発する必要なありません(100%リリースの際はいくつかの仕組みを導入して100%の負荷に耐えられるように追加開発します)。
例えば、レコメンドはレコメンド情報を更新する頻度などでも精度が変わるので、そういった部分も100%リリースを見据えて検討しておく必要があります。
採用するアルゴリズムによってシステム構成がかわったりするので、この時点で候補のアルゴリズムを選定します。
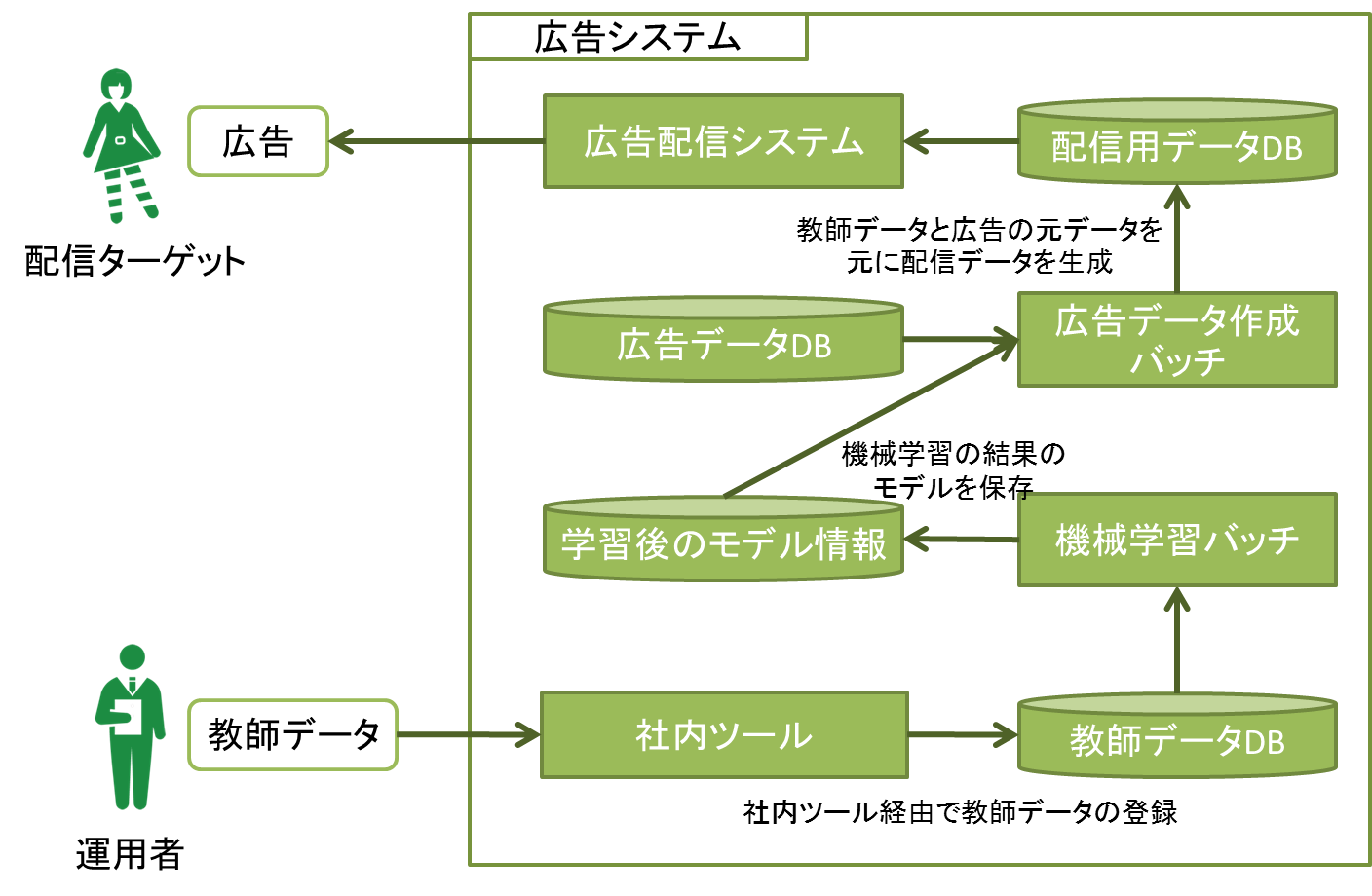
ここで忘れやすいのは、教師あり学習の場合の教師データの運用方法です。
内容によってはログやデータベースから機械的に取得するのが難しい場合などがあります。その場合は、工数にも関わってくるため、人手で教師データを追加したりするための運用フローや社内ツールなども視野に入れる必要があります。
例えば、広告配信において、元データには含まれているけれどもバナー画像にとあるものが写っている場合は出さないようにしたい、という状況だとします。その場合、機械学習(などを使って)配信していいか配信してはいけないかを分類する必要があります。これを実現するには、例えば以下の図のように、運用者を立てて定期あるいは非定期で教師データを更新をかけたりする必要があります(もちろんケースバイケースですが)。

教師データを適宜追加する場合のシステム構成例
A/Bテストの方法については、例えば以下の部分を検討します。
- 対象ユーザの属性(例えばサイトへのアクセスが多い人など)
- トラフィック(既存アルゴリズムは全体の何%、新規アルゴリズム1は全体の何%、新規アルゴリズム2は全体の何%、…)
- A/Bテストを実施する場所(例えば外部サイトなど)
- 配信条件(例えば特定のサイズの広告枠のみなど)
- テスト期間(最低限、仮説検定が使える期間は行う)
また、私は基本的にはいつもユーザ固定でテストします。例えば、ユーザ1にはテスト期間中は常に新規アルゴリズム1を出す、といったことです。
ユーザ固定することで、露出回数による効果の違いなども分析できます。
A/Bテストで大事なのは比較対象のテスト条件は必ず同じにすることです。なので、アルゴリズムの違い以外は可能な限り条件をあわせないと、本当の効果が分かりません。
4. 工数を獲得するための承認
ここも機械学習にかかわらない部分になります。
ステップ1,2の調査を元に資料を作成して上司・事業部を説得します。
もし可能であれば、簡単でもデモを用意できるとより説得しやすくなります。
承認をもらえれば、これで晴れてプロジェクトとして動かせるようになると思います。
5. オフライン評価用のシステム詳細設計・構築・テスト
ステップ5と6は、今まで保存していたシステムのログや場合によっては公開されているデータセットを使って、オフラインで評価ができる場合に実施します。また、ある程度大きな会社であれば社内向けに出して評価することもできると思います。
オフライン評価では基本的にはバッチを開発することになります。基本的には普通のバッチ開発と同じになります。
今後の工程のために、アルゴリズムの速度的なパフォーマンスを計測しておくといいと思います。
6. オフライン評価
ステップ5で構築したシステムに対して、用意していたデータを投入して評価します。
評価の方法は色々ありますが、教師あり学習の場合は
- 分類
- 回帰
といった普通の機械学習の方法で評価をしてます。
ただし、既存のシステムに対して機械学習を適用する場合は、これらに加えて既存の方法と比べてどうかを調べる必要があります。
その場合には、A/Bテストのときにも利用しますが、仮説検定を利用しています。
私は基本的に仮説検定の中のt検定(旧・新アルゴリズムのパフォーマンスの平均値がを利用します。
t検定はExcelで楽にできるので、以下の方法でやってます。

必要に応じてステップ5とこれを繰り返して、最終的な候補アルゴリズムとハイパーパラメタを決めます。
7. A/Bテストを実施するための承認
オフライン評価でいい結果が出た場合は、ここでA/Bテストの工程に移るために承認を上司・事業部に承認を得ます。
もちろんですが、例えば広告などを外部のサイトで出したりする場合は、この時に事業部経由などでテスト対象サイトの管理者と交渉するなどが必要になります。
その際、オフライン評価や試算結果などを元に、A/Bテストによってどの程度KPIに影響があるかを伝えておく必要があります。
8. A/Bテスト用のシステム詳細設計・構築・テスト
オフライン評価のときは基本的にはバッチでしたが、ここからはUIなども含まれます。
しかし、100%リリースの負荷を耐える設計にする必要はなく、運用の社内ツールなどもこの時点では不要です。
それ以外は普通のシステム開発と同じです。
9. A/Bテスト
本番リリースして、毎日レポートやログを元に、比較対象の日次KPIおよび仮説を元に各種分析をしていきます。
バンディットアルゴリズムの場合は、どのアルゴリズムの露出割合が多いかを追っていく形になるかと思います。
10. 100%リリース承認
A/Bテストの結果を元に上司・事業部を説得します。
11. 100%リリース用のシステム詳細設計・構築・テスト
A/Bテストではテスト用の負荷を想定し、さらに運用システムの構築はしていないので、ここで残りの部分を構築します。
アクセス負荷が高いシステムについて、リアルタイムで学習していくオンライン学習を行う予定の場合、アルゴリズムによりますが100%の負荷に耐えられるようにするのは大変な場合があります。
というのも、モデルを更新するために全サーバが同じDBにアクセスすることによってレスポンス速度が低下したりする可能性があるからです。
アルゴリズム自体を変えてしまうと、A/Bテストの結果が無意味なってしまうので、この時点でアルゴリズムに変更を加える必要が無いように、ステップ3のあたりで負荷のこともある程度は考えておくべきです。
例えば以下のようにすれば1つのDBに対して負荷を下げる事ができます。サーバごとにDB(基本的にはキャッシュかメモリになります)を持ち、リアルタイムの更新はそこで行い、定期的にマスターに情報を統合しマスターからスレーブ(?)にコピーします。もちろん統合の仕方によっては、不整合が生じてうまく学習できないケースもあるので、利用するアルゴリズム次第になります。

12. 100%リリースと最終評価
テストで利用した環境と実際の環境では効果が異なることがあるので効果の最終チェックをします。
この段階では、単純な比較ができないので、リリース前後のKPIの推移をみます。
最終評価でも問題なければあとは保守・運用・改善を行っていくだけです。
さいごに
機械学習を用いたシステム開発は普通のシステム開発に比べて、オフライン評価・A/Bテストの繰り返しが必要になり、事前の効果見積もりも難しいです。
なので、機械学習への理解が乏しい職場の場合は、デモとオフライン評価の結果を用いて、イメージしやすく期待する効果も数値で分かる状態で説得するのが良いと思います。
誤解を与えないための補足ですが、この記事では機械学習を導入する前提で書いています。実際には分析した結果、KPIを改善するための方法として機械学習が適切であったから適用するという流れであるべきです。
もしかしたら、後ほどいくつかのパートにサンプルデータ・コード・結果などを載せるかもしれません。
以上です。読んでいただきありがとうございました。
明日は、 @kaneshin さんによる記事の予定です。お楽しみに!
この記事へのコメントはありません。